


What is Data?
Data is a collection of a distinct small unit of information. It can be used in a variety of forms like text, numbers, media, bytes, etc. it can be stored in pieces of paper or electronic memory, etc.
What is a Database?
A database is an organized collection of data, so that it can be easily accessed and managed.
You can organize data into tables, rows, columns, and index it to make it easier to find relevant information.
There are many databases available like MySQL, Sybase, Oracle, MongoDB, Informix, PostgreSQL, SQL Server,Microsoft Access , dBASE ,FoxPro,SQLite ,IBM DB2,MariaDB.
Modern databases are managed by the database management system (DBMS).
SQL or Structured Query Language is used to operate on the data stored in a database. SQL depends on relational algebra and tuple relational calculus.
A cylindrical structure is used to display the image of a database.

Relational database model has two main terminologies called instance and schema.
The instance is a table with rows or columns
Schema specifies the structure, like name of the relation, type of each column and name.
This model uses some mathematical concept like set theory and predicate logic.
Cloud database
Cloud database facilitates you to store, manage, and retrieve their structured, unstructured data via a cloud platform.
Some best cloud options are:
AWS (Amazon Web Services)
Snowflake Computing
Oracle Database Cloud Services
Microsoft SQL server
Google cloud spanner
Advantages of cloud database
Lower costs,Automated,Increased accessibility
NoSQL Database
A NoSQL database is an approach to design such databases that can accommodate a wide variety of data models.
NoSQL databases are useful for a large set of distributed data.
Some examples of NoSQL database system with their category are:
MongoDB, CouchDB, Cloudant (Document-based)
Memcached, Redis, Coherence (key-value store)
HBase, Big Table, Accumulo (Tabular)
Advantage of NoSQL
High Scalability,High Availability
Disadvantage of NoSQL
Open source,Management challenge,GUI is not available,Backup
The Object-Oriented Databases
The object-oriented databases contain data in the form of object and classes. Objects are the real-world entity, and types are the collection of objects.
Object-oriented databases hold the rules of object-oriented programming. An object-oriented database management system is a hybrid application.
Object-oriented programming properties
Objects
Classes
Inheritance
Polymorphism
Encapsulation
Relational database properties
Atomicity
Consistency
Integrity
Durability
Concurrency
Query processing
Graph Databases
A graph database is a NoSQL database. It is a graphical representation of data. It contains nodes and edges.
A node represents an entity, and each edge represents a relationship between two edges.

It is mostly used in supply chain management, identifying the source of IP telephony.
DBMS (Data Base Management System)
Database management System is software which is used to store and retrieve the database. For example, Oracle, MySQL, etc.; these are some popular DBMS tools.
Advantage of DBMS
Controls redundancy,Data sharing,Backup,Multiple user interfaces
Disadvantage of DBMS
Size,Cost,Complexity
RDBMS (Relational Database Management System)
The word RDBMS is termed as 'Relational Database Management System.' It is represented as a table that contains rows and column.
RDBMS is based on the Relational model; it was introduced by E. F. Codd.
A relational database contains the following components:
Table
Record/ Tuple
Field/Column name /Attribute
Instance
Schema
Keys
An RDBMS is a tabular DBMS that maintains the security, integrity, accuracy, and consistency of the data.
Here, are the important landmarks from the history of DBMS:
1960 – Charles Bachman designed the first DBMS system
1970 – Codd introduced IBM’S Information Management System (IMS)
1976- Peter Chen coined and defined the Entity-relationship model, also known as the ER model
1980 – Relational Model becomes a widely accepted database component
1985- Object-oriented DBMS develops.
1990s- Incorporation of object-orientation in relational DBMS.
1991- Microsoft ships MS access, a personal DBMS, and that displaces all other personal DBMS products.
1995: First Internet database applications
1997: XML applied to database processing. Many vendors begin to integrate XML into DBMS products.
DBMS vs. Flat File
| DBMS | Flat File Management System | | --- | --- | | Multi-user access | It does not support multi-user access | | Design to fulfill the need of small and large businesses | It is only limited to smaller DBMS systems. | | Remove redundancy and Integrity. | Redundancy and Integrity issues | | Expensive. But in the long term Total Cost of Ownership is cheap | It’s cheaper | | Easy to implement complicated transactions | No support for complicated transactions |
Users of DBMS
Following are the various category of users of DBMS
| Component Name | Task |
| Application Programmers | The Application programmers write programs in various programming languages to interact with databases. |
| Database Administrators | Database Admin is responsible for managing the entire DBMS system. He/She is called Database admin or DBA. |
| End-Users | The end users are the people who interact with the database management system. They conduct various operations on databases like retrieving, updating, deleting, etc. |
Types of DBMS
The main Four Types of Database Management Systems are:
Hierarchical database
Network database
Relational database
Object-Oriented database
1)In a Hierarchical database, model data is organized in a tree-like structure. Data is Stored Hierarchically (top-down or bottom-up) format. Data is represented using a parent-child relationship. In Hierarchical DBMS, parents may have many children, but children have only one parent.
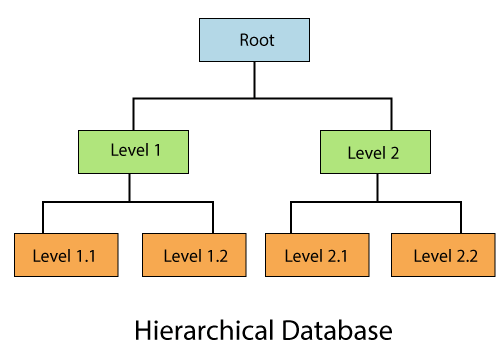
2)Network Model-> The network database model allows each child to have multiple parents. It helps you to address the need to model more complex relationships like the orders/parts many-to-many relationship. In this model, entities are organized in a graph which can be accessed through several paths.
3)Relational Model Relational DBMS is the most widely used DBMS model because it is one of the easiest. This model is based on normalizing data in the rows and columns of the tables. Relational model stored in fixed structures and manipulated using SQL.
4)Object-Oriented Model In the Object-oriented Model data is stored in the form of objects. The structure is called classes which display data within it. It is one of the components of DBMS that defines a database as a collection of objects that stores both data members’ values and operations.
Personal Database
Collecting and storing data on the user's system defines a Personal Database. This database is basically designed for a single user.
Advantage of Personal Database
It is simple and easy to handle.
It occupies less storage space as it is small in size.
Operational DatabaseThe type of database which creates and updates the database in real-time. It is basically designed for executing and handling the daily data operations in several businesses. For example, An organization uses operational databases for managing per day transactions.
Enterprise Database
Large organizations or enterprises use this database for managing a massive amount of data. It helps organizations to increase and improve their efficiency. Such a database allows simultaneous access to users.
Advantages of Enterprise Database:
Multi processes are supportable over the Enterprise database.
It allows executing parallel queries on the system.
When not to use a DBMS system?
Although DBMS system is useful, it is still not suited for the specific task mentioned below:
Not recommended when you do not have the budget or the expertise to operate a DBMS. In such cases, Excel/CSV/Flat Files could do just fine.
csv--comma seperated values-file is a text file that has a specific format which allows data to be saved in a table structured format.
For Web 2.0 applications, it’s better to use NoSQL DBMS
- DBMS is widely used in Banking, Airlines, Telecommunication, Finance, and other industries.
Need for DBMS
A Data Base Management System is a system software for easy, efficient and reliable data processing and management. It can be used for:
Creation of a database.
Retrieval of information from the database.
Updating the database.
Managing a database
Multiple User Interface
Data scalability, expandability and flexibility: We can change schema of the database, all schema will be updated according to it.
Overall the time for developing an application is reduced.
Security: Simplifies data storage as it is possible to assign security permissions allowing restricted access to data
Data organization: DBMS allow users to organize large amounts of data in a structured and systematic way. Data is organized into tables, fields, and records, making it easy to manage, store, and retrieve information.
Data scalability: DBMS are designed to handle large amounts of data and are scalable to meet the growing needs of organizations. As organizations grow, DBMS can scale up to handle increasing amounts of data and user traffic
DBMS in detail
1.Data ** Organization and Management-->**One of the primary needs for a DBMS is data organization and management. DBMSs allow data to be stored in a structured manner, which helps in easier retrieval and analysis. A well-designed database schema enables faster access to information, reducing the time required to find relevant data. A DBMS also provides features like indexing and searching, which make it easier to locate specific data within the database. This allows organizations to manage their data more efficiently and effectively.
2.Data ** Security and Privacy-->**DBMSs provide a robust security framework that ensures the confidentiality, integrity, and availability of data. They offer authentication and authorization features that control access to the database. DBMSs also provide encryption capabilities to protect sensitive data from unauthorized access. Moreover, DBMSs comply with various data privacy regulations such as the GDPR, HIPAA, and CCPA, ensuring that organizations can store and manage their data in compliance with legal requirements.
3.Data ** Integrity and Consistency-->**Data integrity and consistency are crucial for any database. DBMSs provide mechanisms that ensure the accuracy and consistency of data. These mechanisms include constraints, triggers, and stored procedures that enforce data integrity rules. DBMSs also provide features like transactions that ensure that data changes are atomic, consistent, isolated, and durable (ACID).
**4.Concurrent Data Access-->**A DBMS provides a concurrent access mechanism that allows multiple users to access the same data simultaneously. This is especially important for organizations that require real-time data access. DBMSs use locking mechanisms to ensure that multiple users can access the same data without causing conflicts or data corruption.
5.Data ** Analysis and Reporting-->**DBMSs provide tools that enable data analysis and reporting. These tools allow organizations to extract useful insights from their data, enabling better decision-making. DBMSs support various data analysis techniques such as OLAP, data mining, and machine learning. Moreover, DBMSs provide features like data visualization and reporting, which enable organizations to present their data in a visually appealing and understandable way.
**6.Scalability and Flexibility-->**DBMSs provide scalability and flexibility, enabling organizations to handle increasing amounts of data. DBMSs can be scaled horizontally by adding more servers or vertically by increasing the capacity of existing servers. This makes it easier for organizations to handle large amounts of data without compromising performance. Moreover, DBMSs provide flexibility in terms of data modeling, enabling organizations to adapt their databases to changing business requirements.
**7.Cost-Effectiveness-->**DBMSs are cost-effective compared to traditional file-based systems. They reduce storage costs by eliminating redundancy and optimizing data storage. They also reduce development costs by providing tools for database design, maintenance, and administration. Moreover, DBMSs reduce operational costs by automating routine tasks and providing self-tuning capabilities.
Difference between File System and DBMS
File System Approach
File based systems were an early attempt to computerize the manual system. It is also called a traditional based approach in which a decentralized approach was taken where each department stored and controlled its own data with the help of a data processing specialist. The main role of a data processing specialist was to create the necessary computer file structures, and also manage the data within structures and design some application programs that create reports based on file data.
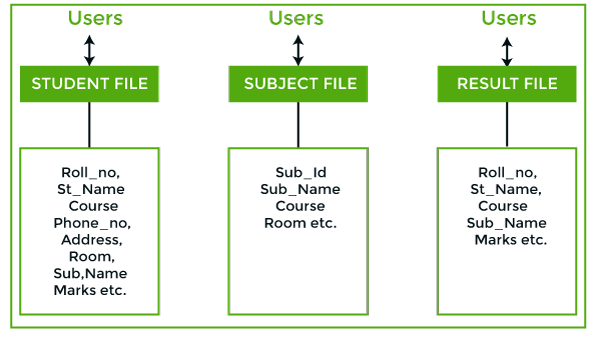
Some fields are duplicated in more than one file, which leads to data redundancy. So to overcome this problem, we need to create a centralized system, i.e. DBMS approach.
DBMS: A database approach is a well-organized collection of data that are related in a meaningful way which can be accessed by different users but stored only once in a system. The various operations performed by the DBMS system are: Insertion, deletion, selection, sorting etc.
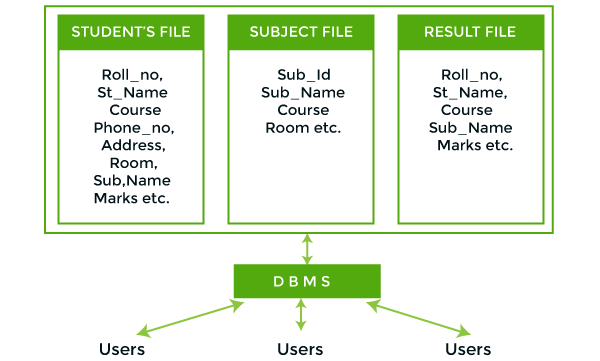
In the above figure, duplication of data is reduced due to centralization of data.
There are the following differences between DBMS and File systems:
| Basis | DBMS Approach | File System Approach |
| Meaning | DBMS is a collection of data. In DBMS, the user is not required to write the procedures. | The file system is a collection of data. In this system, the user has to write the procedures for managing the database. |
| Sharing of data | Due to the centralized approach, data sharing is easy. | Data is distributed in many files, and it may be of different formats, so it isn't easy to share data. |
| Data Abstraction | DBMS gives an abstract view of data that hides the details. | The file system provides the detail of the data representation and storage of data. |
| Security and Protection | DBMS provides a good protection mechanism. | It isn't easy to protect a file under the file system. |
| Recovery Mechanism | DBMS provides a crash recovery mechanism, i.e., DBMS protects the user from system failure. | The file system doesn't have a crash mechanism, i.e., if the system crashes while entering some data, then the content of the file will be lost. |
| Manipulation Techniques | DBMS contains a wide variety of sophisticated techniques to store and retrieve the data. | The file system can't efficiently store and retrieve the data. |
| Concurrency Problems | DBMS takes care of Concurrent access of data using some form of locking. | In the File system, concurrent access has many problems like redirecting the file while deleting some information or updating some information. |
| Where to use | Database approach used in large systems which interrelate many files. | File system approach used in large systems which interrelate many files. |
| Cost | The database system is expensive to design. | The file system approach is cheaper to design. |
| Data Redundancy and Inconsistency | Due to the centralization of the database, the problems of data redundancy and inconsistency are controlled. | In this, the files and application programs are created by different programmers so that there exists a lot of duplication of data which may lead to inconsistency. |
| Structure | The database structure is complex to design. | The file system approach has a simple structure. |
| Data Independence | In this system, Data Independence exists, and it can be of two types.Logical Data IndependencePhysical Data Independence | In the File system approach, there exists no Data Independence. |
| Integrity Constraints | Integrity Constraints are easy to apply. | Integrity Constraints are difficult to implement in file system. |
| Data Models | In the database approach, 3 types of data models exist:Hierarchal data modelsNetwork data modelsRelational data models | In the file system approach, there is no concept of data models exists. |
| Flexibility | Changes are often a necessity to the content of the data stored in any system, and these changes are more easily with a database approach. | The flexibility of the system is less as compared to the DBMS approach. |
| Examples | Oracle, SQL Server, Sybase etc. | Cobol, C++ etc. |
Difference Between Two-Tier And Three-Tier database architecture
1. Two-Tier Database Architecture –
In two-tier, the application logic is either buried inside the User Interface on the client or within the database on the server (or both). With two-tier client/server architectures, the user system interface is usually located in the user’s desktop environment and the database management services are usually in a server that is a more powerful machine that services many clients.
2. Three-Tier Database Architecture –
In three-tier, the application logic or process lives in the middle-tier, it is separated from the data and the user interface. Three-tier systems are more scalable, robust and flexible. In addition, they can integrate data from multiple sources. In the three-tier architecture, a middle tier was added between the user system interface client environment and the database management server environment. There are a variety of ways of implementing this middle tier, such as transaction processing monitors, message servers, or application servers.
Difference Between Two-Tier And Three-Tier Database Architecture
| S.NO | Two-Tier Database Architecture | Three-Tier Database Architecture |
|---|---|---|
| 1 | It is a Client-Server Architecture. | It is a Web-based application. |
| 2 | In two-tier, the application logic is either buried inside the user interface on the client or within the database on the server (or both). | In three-tier, the application logic or process resides in the middle-tier, it is separated from the data and the user interface. |
| 3 | Two-tier architecture consists of two layers : Client Tier and Database (Data Tier). | Three-tier architecture consists of three layers : Client Layer, Business Layer and Data Layer. |
| 4 | It is easy to build and maintain. | It is complex to build and maintain. |
| 5 | Two-tier architecture runs slower. | Three-tier architecture runs faster. |
| 6 | It is less secured as client can communicate with database directly. | It is secured as client is not allowed to communicate with database directly. |
| 7 | It results in performance loss whenever the users increase rapidly. | It results in performance loss whenever the system is run on Internet but gives more performance than two-tier architecture. |
| 8 | Example – Contact Management System created using MS-Access or Railway Reservation System, etc. | Example – Designing registration form which contains text box, label, button or a large website on the Internet, etc. |
##Database language
Structured Query Language(SQL) as we all know is the database language by the use of which we can perform certain operations on the existing database and also we can use this language to create a database.
SQL uses certain commands like CREATE, DROP, INSERT,DELETE(CRUD) etc. to carry out the required tasks.
SQL commands are like instructions to a table. It is used to interact with the database with some operations. It is also used to perform specific tasks, functions, and queries of data. SQL can perform various tasks like creating a table, adding data to tables, dropping the table, modifying the table, set permission for users.
These SQL commands are mainly categorized into five categories:
DDL – Data Definition Language
DQL – Data Query Language
DML – Data Manipulation Language
DCL – Data Control Language
TCL – Transaction Control Language.
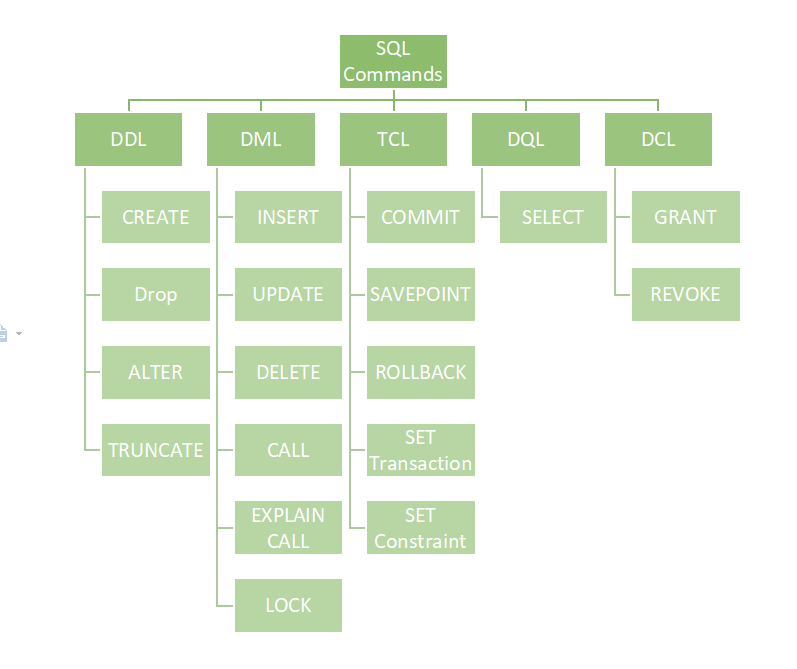
DDL (Data Definition Language)
DDL or Data Definition Language actually consists of the SQL commands that can be used to define the database schema. It simply deals with descriptions of the database schema and is used to create and modify the structure of database objects in the database. DDL is a set of SQL commands used to create, modify, and delete database structures but not data. These commands are normally not used by a general user, who should be accessing the database via an application.
List of DDL commands:
CREATE: This command is used to create the database or its objects (like table, index, function, views, store procedure, and triggers).
DROP: This command is used to delete objects from the database.
ALTER: This is used to alter the structure of the database.
TRUNCATE: This is used to remove all records from a table, including all spaces allocated for the records are removed.
COMMENT: This is used to add comments to the data dictionary.
RENAME: This is used to rename an object existing in the database.
DQL (Data Query Language)
DQL statements are used for performing queries on the data within schema objects. The purpose of the DQL Command is to get some schema relation based on the query passed to it. We can define DQL as follows it is a component of SQL statement that allows getting data from the database and imposing order upon it. It includes the SELECT statement. This command allows getting the data out of the database to perform operations with it. When a SELECT is fired against a table or tables the result is compiled into a further temporary table, which is displayed or perhaps received by the program i.e. a front-end.
List of DQL:
SELECT: It is used to retrieve data from the database.
DML(Data Manipulation Language)
The SQL commands that deal with the manipulation of data present in the database belong to DML or Data Manipulation Language and this includes most of the SQL statements. It is the component of the SQL statement that controls access to data and to the database. Basically, DCL statements are grouped with DML statements.
List of DML commands:
INSERT: It is used to insert data into a table.
UPDATE: It is used to update existing data within a table.
DELETE: It is used to delete records from a database table.
LOCK: Table control concurrency.
Merge: It performs UPSERT operation, i.e., insert or update operations.
CALL: Call a PL/SQL or JAVA subprogram.(PL->Procedural language)
EXPLAIN PLAN: It describes the access path to data.
DCL (Data Control Language)
DCL includes commands such as GRANT and REVOKE which mainly deal with the rights, permissions, and other controls of the database system.
List of DCL commands:
GRANT: This command gives users access privileges to the database.
Syntax:
GRANT SELECT, UPDATE ON MY_TABLE TO SOME_USER, ANOTHER_USER;
REVOKE: This command withdraws the user’s access privileges given by using the GRANT command.
Syntax:
REVOKE SELECT, UPDATE ON MY_TABLE FROM USER1, USER2;
There are the following operations which have the authorization of Revoke:
CONNECT, INSERT, USAGE, EXECUTE, DELETE, UPDATE and SELECT.
TCL (Transaction Control Language)
Transactions group a set of tasks into a single execution unit. Each transaction begins with a specific task and ends when all the tasks in the group successfully complete. If any of the tasks fail, the transaction fails. Therefore, a transaction has only two results: success or failure. You can explore more about transactions here. Hence, the following TCL commands are used to control the execution of a transaction:
BEGIN: Opens a Transaction.
COMMIT: Commits a Transaction.
Syntax:
COMMIT;
ROLLBACK: Rollbacks a transaction in case of any error occurs.
Syntax:
ROLLBACK;
SAVEPOINT: Sets a save point within a transaction.
Syntax:
SAVEPOINT SAVEPOINT_NAME;
IMPORTANT TERMS
Instances,Schema and Subschema
Instances in DBMS
In simple words, it is the snapshot of the database taken at a particular moment. It can also be described in more significant way as the collection of the information stored in the database at that particular moment. Instance can also be called as the database state or current set of occurrence due the fact that it is information that is present at the current state.
Every time we update the state say we insert, delete or modify the value of the data item in the record, it changes from one state to other. At the given time, each schema has its own set of instances.
Every time we update the state say we insert, delete or modify the value of the data item in the record, it changes from one state to other. At the given time, each schema has its own set of instances.
Lets take an example to understand in a much better way,
An organization with an employees database will have three different instances such as production that is used to monitor the data right at that moment, per-production that is used to test new functionality prior to release of production and the development that is used by database developers to create new functionality.
Schema in DBMS
It is the overall description or the overall design of the database specified during the database design. Important thing to be remembered here is it should not be changed frequently. Basically, it displays the record types(entity),names of data items(attribute) but not the relation among the files.
Interesting point is the values in schema might change but not the structure of schema.
To understand it well, Schema can be assumed as a framework where in the values of data items are to be fitted, these values can be changed but not frame/format of the schema.
Consider the below two examples of schema for database stores and discounts
STORES
store_name
store_id
store_add
city
state
zip_code
DISCOUNTS
discount_type
store_id
lowqty
highqty
discount
The former example shows the schema for stores displaying the name of the store, store id,address,city and state in which it is located and the zip code of respective location.
The latter example is all about schema of discounts that clearly shows the type,id and quality,thus we can now relate to the fact that schema only displays the record types (entities) and names of data items(attributes) but does not show the relation among the files.
Schema can be partitioned as logical schema and physical schema.
Look at the below diagram
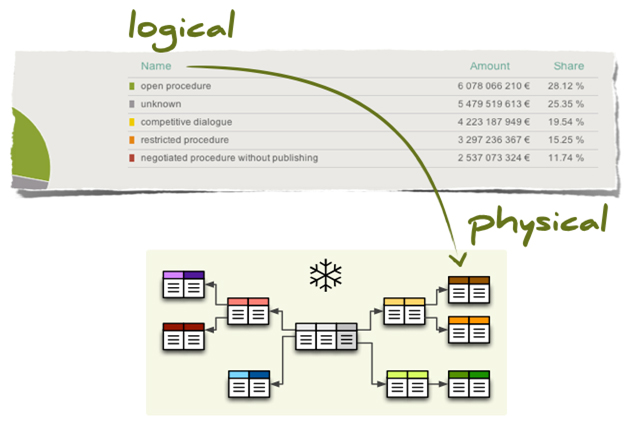
Here,former part shows the logical schema which is concerned with the data structure with exploring data structure offered to DBMS so that schema is very easy for the computer to understand.
The latter part that is the physical schema is concerned with the way or the manner in which conceptual database gets represented in the computer as it is stored in the database.Physical schema is hidden behind the logical schema and thus can be be modified without affecting the application programs
Database management system provides data definition language(DDL) and document schema definition language(DSDL) to specify both logical and physical schema.
Sub schema in DBMS
It can be defined as the subset or sub-level of schema that has the same properties as the schema. In simple words it is just a effective plan or the schema for the view. Well, it is interesting to note that it provides the users a window through which the user can view only that part of database which is of matter of interest to him. It Identifies subset of areas, sets, records, data names defined in database that is of interest to him. Thus a portion of database can be seen by application programs and different application programs has different view of data.
Quickly we can summarize the above things, information/data in database at particular moment is known as instance,physical arrangement of data as it appears in database can be defined as schema, and the logical view of data as it appears to the application can be called as sub schema.
What is Data Abstraction in DBMS and what are its three levels?
Data Abstraction
example-->Have you ever wondered how the same website has different views for different users? For example, a college website has a different view for student, faculty and the dean. A student will see the details of his/her attendance, homework, etc. While a faculty will see his/her class time-table and all information that is related to a faculty. We see only that much amount of data which is necessary and other data is hidden from us. So, what is this phenomenon called? Yes, you got it right. This phenomenon is called data abstraction. In this blog, we will learn about data abstraction and we will also see the three levels of abstraction in DBMS. So, let's get started.
Definition-Data Abstraction refers to the process of hiding irrelevant details from the user.
what is the meaning of irrelevant details? Let's understand this with one example. Example: If we want to access any mail from our Gmail then we don't know where that data is physically stored i.e is the data present in India or USA or what data model has been used to store that data? We are not concerned about these things. We are only concerned with our email. So, information like these i.e. location of data and data models are irrelevant to us and in data abstraction, we do this only. Apart from the location of data and data models, there are other factors that we don't care of. We hide the unnecessary data from the user and this process of hiding unwanted data is called Data Abstraction.
There are mainly three levels of data abstraction and we divide it into three levels in order to achieve Data Independence .
Data Independence means users and data should not directly interact with each other.
The user should be at a different level and the data should be present at some other level.
These three levels of data abstraction are:
View Level
Conceptual Level(Logical level)
Physical Level(Internal schema)
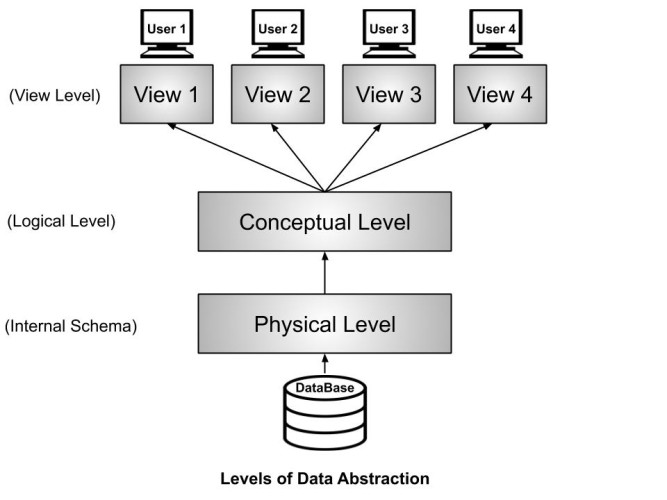
View Level or External Schema
This level tells the application about how the data should be shown to the user.
Example: If we have a login-id and password in a university system, then as a student, we can view our marks, attendance, fee structure, etc. But the faculty of the university will have a different view. He will have options like salary, edit marks of a student, enter attendance of the students, etc. So, both the student and the faculty have a different view. By doing so, the security of the system also increases. In this example, the student can't edit his marks but the faculty who is authorized to edit the marks can edit the student's marks. Similarly, the dean of the college or university will have some more authorization and accordingly, he will has his view. So, different users will have a different view according to the authorization they have.
Conceptual Level or Logical Level
This level tells how the data is actually stored and structured. We have different data models by which we can store the data(You can read more about the different types of data model from here ). Example : Let us take an example where we use the relational model for storing the data. We have to store the data of a student, the columns in the student table will be student_name, age, mail_id, roll_no etc. We have to define all these at this level while we are creating the database. Though the data is stored in the database but the structure of the tables like the student table, teacher table, books table, etc are defined here in the conceptual level or logical level. Also, how the tables are related to each other are defined here. Overall, we can say that we are creating a blueprint of the data at the conceptual level.
Physical Level or Internal Schema
As the name suggests, the Physical level tells us that where the data is actually stored i.e. it tells the actual location of the data that is being stored by the user. The Database Administrators(DBA) decide that which data should be kept at which particular disk drive, how the data has to be fragmented, where it has to be stored etc. They decide if the data has to be centralized or distributed. Though we see the data in the form of tables at view level the data here is actually stored in the form of files only. It totally depends on the DBA, how he/she manages the database at the physical level.
So, the Data Abstraction provides us with a different view and help in achieving Data Independence.
Referential Integrity Rule in RDBMS
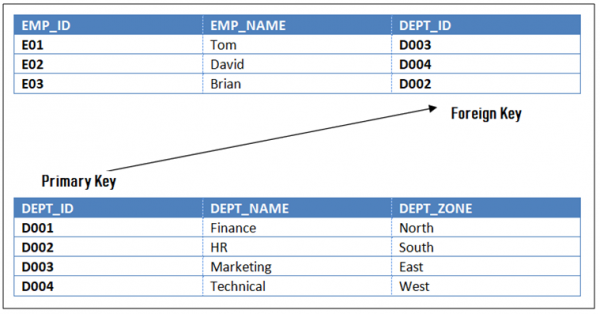
Referential Integrity Rule in DBMS is based on Primary and Foreign Key. The Rule defines that a foreign key have a matching primary key. Reference from a table to another table should be valid.
Referential Integrity Rule example −
<Employee>
EMP_ID | EMP_NAME | DEPT_ID |
<Department>
DEPT_ID | DEPT_NAME | DEPT_ZONE |
The rule states that the DEPT_ID in the Employee table has a matching valid DEPT_ID in the Department table.
To allow join, the referential integrity rule states that the Primary Key and Foreign Key have same data types.
Types of Databases
- Centralized Database,2) Distributed Database->Examples of the Distributed database are Apache Cassandra, HBase, Ignite, etc.
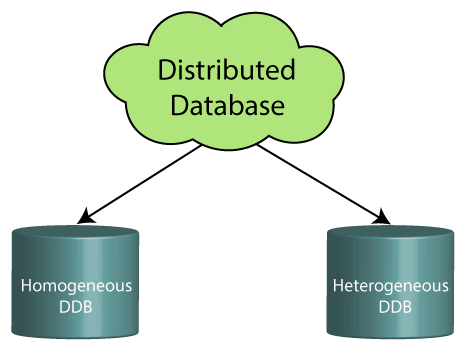
Homogeneous DDB: Those database systems which execute on the same operating system and use the same application process and carry the same hardware devices.
Heterogeneous DDB: Those database systems which execute on different operating systems under different application procedures, and carries different hardware devices.
3) Relational Database->This database is based on the relational data model, which stores data in the form of rows(tuple) and columns(attributes), and together forms a table(relation).
Each table in the database carries a key that makes the data unique from others. Examples of Relational databases are MySQL, Microsoft SQL Server, Oracle, etc.